데이터 분석하는 과정을 EDA(Exploratory Data Anlaysis)라고 말합니다. 데이터를 클렌징하고 구성 및 분포를 확인하고, 통계 및 상관관계 분석 또는 시각화를 통해 데이터를 깊이있게 이해하고 이를 통해 인사이트를 얻는 과정입니다. 파이썬 판다스를 이용하여 EDA하는 과정을 상세하게 다뤄보겠습니다.

파이썬 판다스(Pandas) 데이터프레임으로 EDA(Exploratory Data Analysis, 데이터 분석) 해보기
1. 데이터 로드 및 데이터 클렌징
데이터 로드하기
Scikit learn 패키지에서 로드해서 쓸 수 있는 데이터들이 있는데 이번 포스팅에서는 그 중 하나인 Wine 관련 데이터를 사용하도록 하겠습니다. Wine 데이터는 알코올 농도, 마그네슘 농도 등 와인이 가지는 요소들을 속성으로 가지고 있고, Target은 세가지 다른 품종(0, 1, 2)으로 분류되어있는 데이터입니다. 다음의 코드를 이용하여 데이터를 먼저 로드합니다.
from sklearn.datasets import load_wine
import pandas as pd
# Load the Wine dataset into a variable called 'wine'
wine = load_wine()
# Create a pandas DataFrame from the wine data
df = pd.DataFrame(data=wine.data, columns=wine.feature_names)
# Add the target variable to the DataFrame
df['target'] = wine.target
# Print the first 5 rows of the DataFrame to make sure the data was loaded correctly
print(df.head())그럼 아래와 같이 데이터가 잘 로드되었음을 확인할 수 있습니다.
참고로 여기서 df.head() 함수는 가장 위에있는 5개의 행을 가져오기 위한 함수입니다. 만약 마지막 부분을 가져오고 싶으면 df.tail()을 쓸 수 있습니다. 괄호 안에 숫자를 명시해주면, 해당 갯수만큼의 행을 가져옵니다.
Missing Value 확인하기
본격적인 데이터 분석에 앞서 Missing value (null 값)이 있는지 확인하는 것은 중요합니다. 다음 코드를 통해 dataframe에 빈 값이 있는지 확인할 수 있습니다.
# Check for missing values in the DataFrame
print(df.isnull().sum())예시로 사용한 이 데이터는 missing value가 없었지만, 만약 있는 경우는 missing value를 drop을 하거나, 평균값으로 채워 사용할 수 있습니다.
# Drop any rows with missing values
df = df.dropna()
# Fill missing values with the mean of the column
df = df.fillna(df.mean())Outlier 확인하기
각 속성값이 숫자로 이루어져있기 때문에, Outlier가 있는지 확인하는 것도 중요합니다. 만약 데이터 분석을 마친 후 머신러닝 등으로 데이터를 활용하고자 할 때, outlier 가 섞여있게 되면 퍼포먼스를 악화시키는 원인이 될 수 있기 때문입니다. 따라서 확인하고 필요에 따라 제거를 하는게 좋습니다. 아래 코드는 각 컬럼별 평균값으로부터 3 표준편차 이상 떨어져있는 것을 outlier로 정하고, outlier가 몇개씩 있는지 확인하는 코드입니다.
import numpy as np
# Calculate the mean and standard deviation of each column
means = df.mean()
stds = df.std()
# Check for values that are more than 3 standard deviations from the mean
outliers = {}
for column in df.columns:
is_outlier = np.abs(df[column] - means[column]) > 3 * stds[column]
num_outliers = is_outlier.sum()
if num_outliers > 0:
outliers[column] = num_outliers
# Print the names and number of instances of any columns that have outliers
if len(outliers) > 0:
print("The following columns have outliers:")
for column, num_outliers in outliers.items():
print("- {}: {} outliers".format(column, num_outliers))
else:
print("No columns have outliers.")위에서 확인한 outlier를 삭제하고 싶을 때는 아래코드처럼 해당 outlier를 제외한 부분을 다시 데이터프레임에 넣어주면 됩니다.
# Filter out any rows where any column has a value more than 3 standard deviations from the mean
df = df[~((np.abs(df - means) > 3 * stds).any(axis=1))]
2. 데이터 이해하기
통계 확인하기(Descriptive Statistics)
데이터의 속성들이 숫자들로 이루어져있으므로, 각 컬럼별 통계 수치(평균, 표준편차, 최소값, 중위값, 최대값 등)를 확인할 수 있는 describe() 함수를 사용해봅니다. 데이터가 178개 행으로 이루어져있음을 알 수 있고, 알콜 농도는 평균 13%정도가 되는 것을 확인할 수 있습니다.
# Print summary statistics for each column
print(df.describe())데이터 분포 확인하기
target이 0 또는 1 또는 2 class로 구분이 되어있는데, 각 클래스별로 몇 개씩 분포하고 있는지 확인해보도록 합니다. 우선 각 클래스에 해당하는 데이터 갯수를 카운트하기 위해 데이터프레임의 value_counts()함수를 사용합니다.
# Show the distribution of the target variable
target_counts = df['target'].value_counts()
print(target_counts)
1번 class가 71개로 가장 많고, 0번 class가 59개, 2번 class가 48개임을 확인할 수 있습니다.
데이터 시각화(Data visualizaion)
숫자로 이루어져있는 값들은 히스토그램을 그려 확인하면 훨씬 직관적으로 데이터의 분포를 이해할 수 있습니다. 파이썬의 matplotlib과 seaborn은 다양한 차트 시각화를 지원하는 라이브러리입니다. 아래 코드를 실행하여 각 속성들의 분포를 히스토그램으로 확인할 수 있습니다.
import matplotlib.pyplot as plt
import seaborn as sns
# Create histograms of the numeric columns
df.hist(figsize=(12,10))
plt.tight_layout()
plt.show()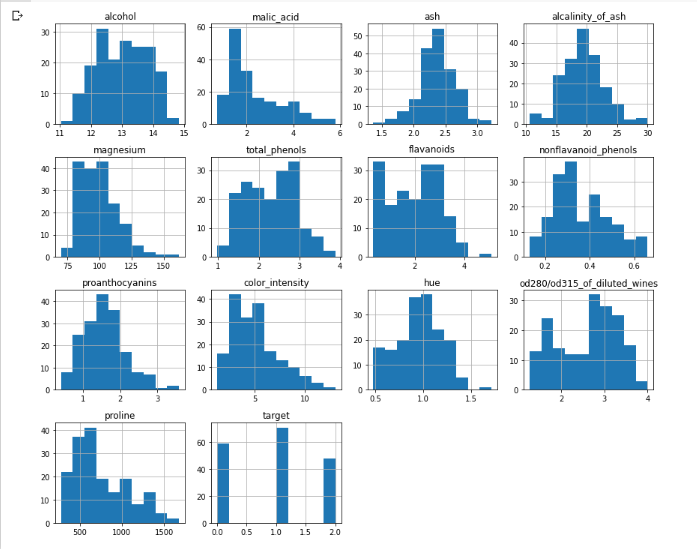
또한 seaborn의 countplot 함수를 이용하여, target 속성의 분포를 나타내는 bar 그래프를 그려보도록 합니다.
# Create a bar plot of the target variable
sns.countplot(x='target', data=df)
plt.show()
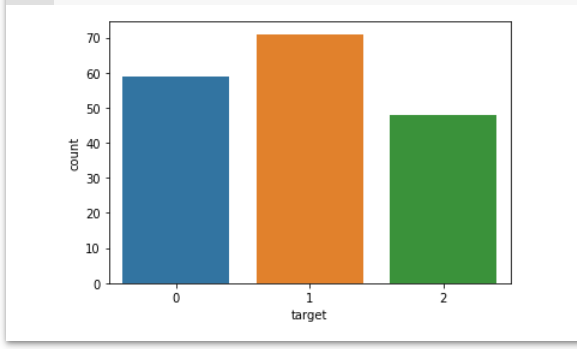
plot을 통해 위에서 확인했던 target 값의 class별 분포를 직관적으로 확인할 수 있습니다.
3. 상관관계 분석(Correlation Analysis)
데이터를 분석할 때 각 속성별 상관관계를 분석하면, 데이터를 깊이 있게 이해하는 데 도움이 됩니다. 상관관계를 분석하기 위해서는 우선 Pierson 상관계수를 구합니다. 아래 코드는 이 상관계수를 구한 다음 통상적으로 강한 상관관계(strong correlation)가 있다고 말할 수 있는 상관계수가 0.7보다 큰 것만 출력하는 예제입니다.
# Create a correlation matrix
corr_matrix = df.corr()
# Find the columns with strong correlation coefficients
strong_corr_cols = corr_matrix[abs(corr_matrix) > 0.7].stack().reset_index().query("level_0 != level_1")
# Sort the results by the absolute value of the correlation coefficients in descending order
strong_corr_cols = strong_corr_cols.assign(abs_corr = strong_corr_cols[0].abs()).sort_values('abs_corr', ascending=False)
# Keep track of the pairs of columns that have already been printed
printed_pairs = set()
# Iterate through the pairs of columns and print their correlation coefficients
for _, row in strong_corr_cols.iterrows():
col1, col2 = row['level_0'], row['level_1']
if (col2, col1) in printed_pairs:
continue
corr_coef = corr_matrix.loc[col1, col2]
print(f"{col1} and {col2}: {corr_coef:.2f}")
printed_pairs.add((col1, col2))
상관관계 분석을 통해 flavanoids, od280/od315_of_diluted_wines, total_phenols 등의 속성이 target에 가장 영향을 많이 주는 속성들임을 확인 할 수 있습니다.
속성들 간의 상관관계를 시각화해서 보려면 상관관계 매트릭스를 heatmap으로 그려서 볼 수도 있습니다.
# Calculate the correlation matrix
corr_matrix = data.corr()
# Set up the Matplotlib figure
f, ax = plt.subplots(figsize=(10, 8))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr_matrix, cmap=cmap, center=0, square=True, linewidths=.5, cbar_kws={"shrink": .5})
# Rotate the tick labels for easier reading
plt.xticks(rotation=45, ha='right')
# Display the plot
plt.show()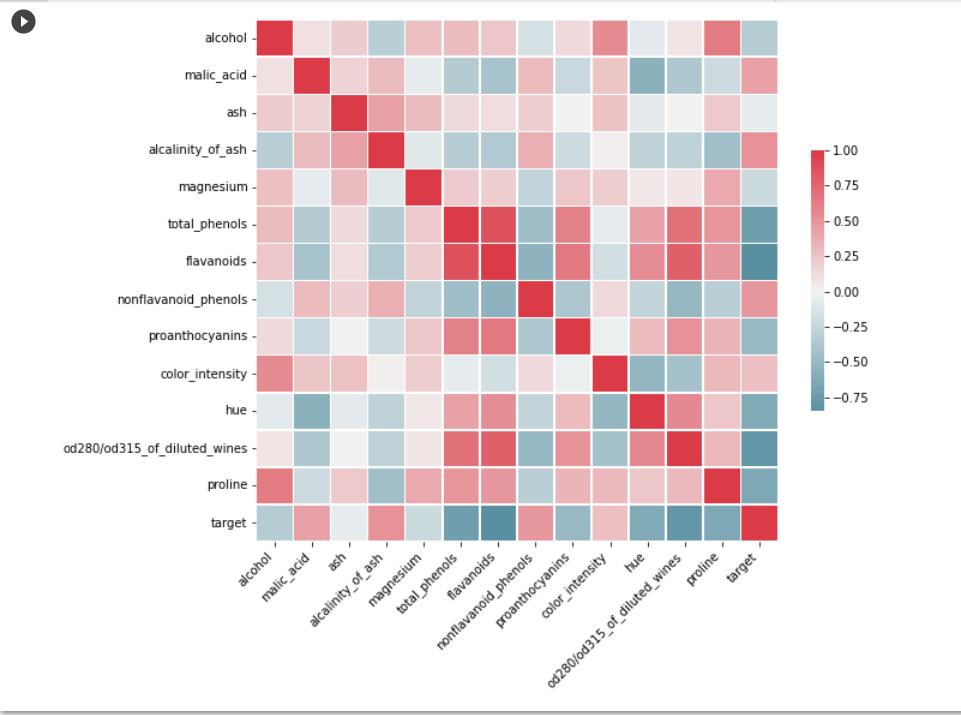
데이터 시각화하는 방법은 이 외에도 정말 많은 방법이 있습니다. 위의 예시는 그 중 가장 많이 사용되는 것을 보여드렸습니다.
결론
이번 포스팅에서는 wine 데이터를 이용하여 어떤 절차로 EDA를 할 수 있는지 알아보았습니다. 처음에는 null value와 outlier 값 확인 및 정리를 통해 데이터를 클렌징하고, 통계 및 데이터 분포 분석을 통해 데이터를 이해하는 단계로 넘어갑니다. 그 후 상관관계 분석을 통해 데이터 속성들 간의 관계를 살펴보고 시각화 해봄으로써 데이터를 더욱 깊게 이해합니다. 이런 EDA 과정을 통해 다음 단계인 머신러닝 등으로 넘어가기 전에 데이터가 어떻게 구성되었는지, 머신러닝 모델에 적용할 때 어떤 속성들을 중점적으로 이용해야할지 등 깊이있게 이해하고 인사이트를 얻을 수 있습니다.
(참고하면 좋은 포스팅)
파이썬으로 웹스크래핑 크롤링 하는 방법 (BeautifulSoup 사용)
웹스크래핑 또는 웹크롤링을 이용해서 웹사이트에서 데이터를 추출해오는 방법에 대해 소개하고자 합니다. 파이썬 라이브러리인 BeautifulSoup을 이용하여 코드 몇줄로 초보자도 쉽게 데이터를 추
datasciencediary.tistory.com
[파이썬] 아직도 for loop만 쓰시나요? list comprehension 으로 간편하게 코딩하기
파이썬에서는 List Comprehension(리스트 컴프리헨션)이라는 강력한 도구를 사용할 수 있다. 주로 for loop이나 while 문을 돌려야 하는 상황에 대신하여 쓸 수 있다. 몇 가지 예제를 보면서 어떻게 활용
datasciencediary.tistory.com
[파이썬] 판다스 데이터프레임 loc 과 iloc 인덱싱 사용법 정복하기
파이썬 판다스 데이터 프레임은 데이터 분석을 위한 아주 기본적인 파이썬의 데이터 구조이다. 데이터 분석에 유용하게 활용할 수 있는 기초적인 데이터프레임 인덱싱 방법인 loc과 iloc의 개념,
datasciencediary.tistory.com
'파이썬 독학' 카테고리의 다른 글
| 파이썬 넘파이 Numpy 사용법 가이드 (0) | 2023.02.20 |
|---|---|
| 파이썬 Matplotlib 사용법 가이드 (0) | 2023.02.19 |
| 파이썬으로 웹스크래핑 크롤링 하는 방법 (BeautifulSoup 사용) (0) | 2023.02.15 |
| 코딩 실력 향상을 위해 LeetCode 리트코드 하세요. (0) | 2023.02.08 |
| [파이썬] 아직도 for loop만 쓰시나요? list comprehension 으로 간편하게 코딩하기 (0) | 2023.02.08 |




댓글