웹스크래핑 또는 웹크롤링을 이용해서 웹사이트에서 데이터를 추출해오는 방법에 대해 소개하고자 합니다. 파이썬 라이브러리인 BeautifulSoup을 이용하여 코드 몇줄로 초보자도 쉽게 데이터를 추출할 수 있습니다. 설치하는 방법부터 최종 데이터 추출까지 코드 예시와 함께 살펴보겠습니다.

웹스크래핑 / 크롤링이란?
특정 웹사이트내 데이터들을 추출해오는 것을 웹스크래핑(Web Scraping) 또는 웹 크롤링(Web Crawling)이라고 말합니다. 어떤 사이트에 나와있는 정보들을 엑셀 등의 잘 정리된 표로 추출을 하고 싶은데, 해당 사이트에서 엑셀 등으로 다운로드 받는 기능을 제공하고 있지 않을 때 하나하나 복사 붙여넣기 하는 대신 웹 스크래핑 또는 웹 크롤링을 이용하면 프로그램으로 데이터를 추출해올 수 있습니다. 이렇게 프로그램으로 데이터를 추출해오게 되면 생산성을 엄청나게 높여주기 때문에 이 기능을 이용한 상용 SW들도 시중에 많이 나와있습니다. (예를들면, 실시간 은행별 잔액을 추출해오는 SW를 만들어 필요로 하는 기관에 판매를 하는 경우를 들 수 있습니다.
사실 요즘은 이런 비즈니스 목적보다도 개인적인 업무효율 향상을 위해 사용하는 경우도 많습니다. 예를 들어 특정 시험을 준비하는 학생이고, 시험과 관련하여 외워야하는 정보들이 특정 사이트에 나와있는 경우, 해당 데이터를 하나하나 수집하려면 시간이 오래걸리게 됩니다. 이럴 때 웹스크래핑 또는 크롤링을 사용하면 데이터 추출하는 시간을 줄여줌으로써 생산성도 향상시키고 효율성도 증대시킬 수 있는 것이죠.
코딩을 할 줄 몰라도 웹스크래핑을 할 수 있나요?
물론입니다. 파이썬에서 제공하는 BeautifulSoup 라이브러리를 활용하면 생각보다 쉽게 초보자들도 웹스크래핑 또는 웹크롤링을 해볼 수 있습니다. 파이썬을 컴퓨터에 설치하지 않은 경우에는 구글 코랩을 활용하여 손쉽게 파이썬 코딩을 바로 해볼 수 있습니다. (구글 코랩 관련 포스팅 참고)
BeautifulSoup을 활용한 웹스크래핑 또는 웹크롤링 해보기
라이브러리 설치
먼저 BeautifulSoup 라이브러리를 설치해야합니다. 본인 컴퓨터에서 직접 코딩을 하는 경우에는 이부분이 필수이고 구글 코랩을 활용하는 경우에는 이미 설치가 되어있기 때문에 이 단계는 건너뛰어도 됩니다. 설치하는 코맨드는 다음과 같습니다.
pip install beautifulsoup4라이브러리 로드하기
설치가 완료됐다면 라이브러리를 로드합니다. 구글 코랩에서 하는 경우는 이 단계부터 따라하면 됩니다. 다음의 코드로 BeautifulSoup 라이브러리와 웹사이트 연결에 필요한 request를 import 합니다.
import requests
from bs4 import BeautifulSoup스크래핑하고자하는 웹페이지 연결하고 html 가져오기
아래 URL 부분에 스크래핑하고자 하는 웹페이지 URL 주소를 넣어줍니다. 저는 예시로 정부24사이트를 넣어봤습니다. 실행했을 때 에러가 나는 경우, 다시 재실행하면 해결되는 경우가 대부분입니다. 해당 페이지로 연결해서 html을 잘 가져왔는지 확인해보려면 제일 마지막줄 주석을 풀어서 html을 print해서 확인해볼 수 있습니다. 웹페이지의 html이 출력이 된다면 정상적으로 연결이 되었고 해당 페이지 html을 추출해온 것입니다.
# 스크래핑하고자하는 URL 넣기
url = "https://www.gov.kr/search/applyMw?Mcode=11166"
# 웹페이지 스크래핑 호출하기 만약 실패하면 재실행해보거나 timeout을 늘려보기
response = requests.get(url, timeout=5)
soup = BeautifulSoup(response.content, "html.parser")
# 해당페이지 html을 잘 가져왔는지 확인하려면 아래 주석 풀고 프린트 되나 확인하기
#print(soup.prettify())
HTML에서 데이터 추출하기
위에서 html을 잘 추출해왔다면, 전체 html에서 내가 가져오고 싶은 부분만 추출을 해내야하는데요. 특정 부분만 추출하는 방법은 아래와 같이 태그를 이용하는 방법, 클래스명과 ID를 이용하는 방법이 있습니다. 데이터를 추출하기 전에 우선 내가 원하는 항목이 어떤 태그로 걸려있는지, 어떤 클래스와 ID를 사용하고 있는지를 확인해야 하는데요. 이는 스크래핑하고자하는 웹페이지에서 "우클릭-페이지 소스보기"를 통해 html소스를 보고, 거기서 Ctrl+F를 눌러 내가 가져오고자 하는 단어를 검색해서 해당부분이 어떤식으로 작성되어있는지 확인할 수 있습니다. 예를 들면 정부24 페이지에서 '토지(임야)대장등본교부' 부분을 가져오고자 하는 경우에 소스보기 페이지에서 해당 단어로 검색하면, 클래스명 "in-bn"으로 되어있고, a 태그의 text로 들어가 있는 것을 확인할 수 있습니다. 이부분은 html 기초내용을 조금 알고 있어야 수월하게 확인할 수 있기는 합니다만, html 기초 내용이 그다지 어렵지 않기 때문에 Youtube 등을 활용해서 1시간정도 할애하면 어느정도 기초를 파악할 수 있습니다.
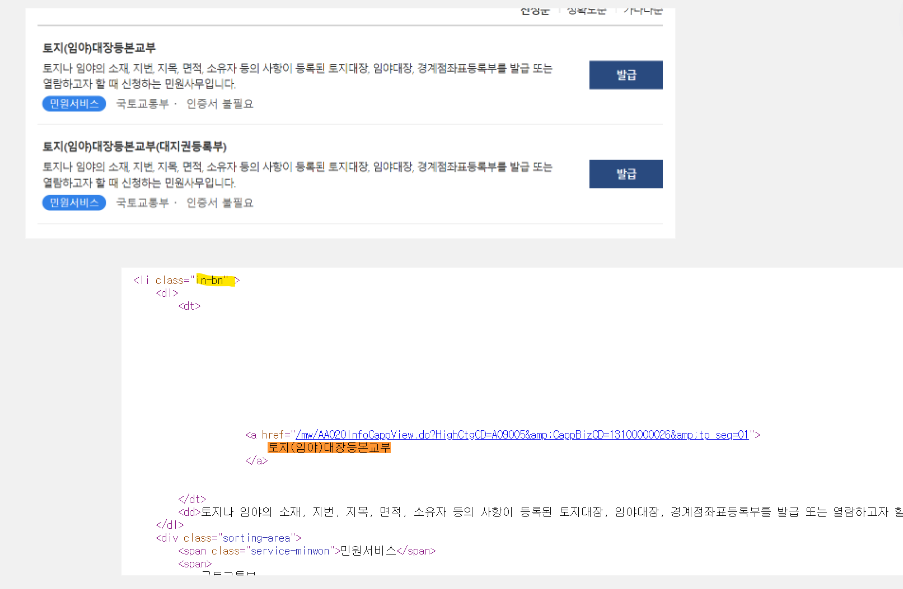
Class 이름 또는 ID로 찾는 방법
위에서 본 예시가 특정 클래스명을 이용해 찾아야하는 부분으로, 이 경우 다음과 같이 코드를 이용하면 됩니다. 이 코드는 데이터를 추출해 판다스 데이터프레임에 넣는 부분까지 포함하고 있습니다. 보통 데이터를 추출해서 엑셀이나 csv형태로 다운로드 받아 사용하는게 편리하기 때문에 판다스 데이터프레임에 로드하는게 좋습니다.
# 스크래핑한 것을 데이터프레임 형태로 저장하기 위해 판다스 로드하기
import pandas as pd
title = []
# 찾고자하는 태그가 속해있는 클래스명으로 찾는법
land_records = soup.find_all(class_="in-bn")
# 해당클래스내의 모든 dt 태그안의 모든 a 태그의 제목 가져오기
for land_record in land_records:
dt = land_record.find("dt")
text = dt.a.get_text(strip=True)
title.append(text)
# 가져온 리스트 데이터프레임에 넣기
df = pd.DataFrame(title, columns=["title"])
# 잘 넣어졌는지 확인
print(df)위의 코드는 다음과 같은 결과값을 추출해줍니다.
title
0 토지(임야)대장등본교부
1 토지(임야)대장등본교부(대지권등록부)
2 토지(임야)대장열람
3 토지(임야)대장열람(대지권등록부)
4 주민등록표등본교부
5 주민등록표초본교부
6 영문 주민등록표등본
7 영문 주민등록표초본
8 건축물대장(발급)
9 건축물대장(열람)Tag 이름으로 찾는 방법
만약 가져오고자 하는 부분이 특정 태그로 되어있다면, 태그명으로 추출할 수도 있습니다. 아래는 p 태그로 되어있는 부분을 모두 가져오는 예시입니다.
paragraphs = soup.find_all("p")
for p in paragraphs:
print(p.text)위에 예시로 들었던 정부24 페이지의 경우, 각 문서에 해당하는 설명이 나와있는 부분을 추가로 추출한다면, html소스에서 해당부분에 dd태그로 구분되어있기 때문에 이 태그를 사용하여 추출할 수 있습니다.
# 그다음 설명에 해당하는 dd태그 문자 모두 가져오기
des = []
land_records = soup.find_all(class_="in-bn")
for land_record in land_records:
dt = land_record.find("dd")
text = dt.get_text(strip=True)
des.append(text)
# 데이터프레임에 열로 추가하기
df['description'] = des
df
위의 코드는 아래와 같은 결과를 추출해줍니다.

결론적으로, 우선 BeautifulSoup 라이브러리를 로드하고 html 소스를 파싱해온 다음에 추출하고자 하는 영역의 html소스를 확인 후 태그, 클래스명, ID 등으로 BeautifulSoup find 또는 find_all 함수를 이용하여 해당 데이터를 추출해올 수 있습니다. 이를 판다스 데이터프레임에 로드하여 최종 엑셀파일 또는 csv형태로 다운로드 받아서 데이터 분석 등에 활용할 수 있습니다. 자칫 어렵게 느껴질 수 있는 웹사이트 연결과 html파싱해오는 부분이 파이썬 라이브러리를 활용하면 코드 몇줄로 모두 해결이 되기 때문에 생각보다 어렵지 않고 초보자들도 손쉽게 따라해볼 수 있습니다. 코딩 하면서 막히는 부분이 있다면 챗gpt를 이용해 해결방법을 찾을 수 있습니다. 자세한 방법은 다음 포스팅을 참고하세요.
미국유학생의 챗 GPT 파이썬 등 코딩, 프로그래밍 활용기
챗 GPT가 나오고 다양한 곳에서 사용이 되고 있다. 블로그 포스팅이나 이메일 내용 수정 등에도 활용할 수 있지만 뭐니 뭐니 해도 코딩 분야에서 엄청난 혁신을 불러일으켰다고 볼 수 있다. 에러
datasciencediary.tistory.com
'파이썬 독학' 카테고리의 다른 글
| 파이썬 Matplotlib 사용법 가이드 (0) | 2023.02.19 |
|---|---|
| 파이썬 판다스 EDA하는 방법 : 데이터 분석 A to Z (0) | 2023.02.16 |
| 코딩 실력 향상을 위해 LeetCode 리트코드 하세요. (0) | 2023.02.08 |
| [파이썬] 아직도 for loop만 쓰시나요? list comprehension 으로 간편하게 코딩하기 (0) | 2023.02.08 |
| [파이썬] 판다스 데이터프레임 loc 과 iloc 인덱싱 사용법 정복하기 (0) | 2023.02.07 |




댓글