사이킷런은 파이썬으로 머신러닝을 할 수 있도록 도와주는 라이브러리입니다. 2010년에 처음 공개되었고 지금까지도 머신러닝 관련 파이썬 패키지로 전세계적으로 가장 많이 쓰이는 라이브러리입니다. 사이킷런(Scikit-learn) 설치 방법과 이를 이용하여 머신러닝 하는 방법을 단계별로 코드 예시와 함께 알아보겠습니다.

사이킷런 설치 방법
사이킷런 설치방법은 본인이 사용하는 환경에 따라 달라집니다. 사이킷런 홈페이지에서 설치방법에 대해 잘 나와있으니 참고하셔도 좋습니다.
로컬에 직접 파이썬을 설치해서 쓰는 경우
커맨드 창을 열어 아래 커맨드를 실행하면 설치할 수 있습니다.
$ pip install -U scikit-learn설치후 설치가 잘되었는지 확인은 아래 커맨드를 통해 할 수 있습니다.
$ python -m pip show scikit-learn # to see which version and where scikit-learn is installed
$ python -m pip freeze # to see all packages installed in the active virtualenv
$ python -c "import sklearn; sklearn.show_versions()"
아나콘다를 사용하고 있는 경우
커맨드 창을 열어 아래 커맨드를 실행하면 설치할 수 있습니다.
$ conda create -n sklearn-env -c conda-forge scikit-learn
$ conda activate sklearn-env설치후 설치가 잘되었는지 확인은 아래 커맨드를 통해 할 수 있습니다.
$ conda list scikit-learn # to see which scikit-learn version is installed
$ conda list # to see all packages installed in the active conda environment
$ python -c "import sklearn; sklearn.show_versions()"
사이킷런은 Numpy, Matplotlib, Scipy 패키지를 기반으로 동작하기 때문에 이 패키지들도 설치가 되어있어야합니다. 만약 설치가 되어있지 않다면 아래 커맨드를 이용하여 설치할 수 있습니다.
$ pip install numpy
$ pip install scipy
$ pip install matplotlib
참고로 구글 코랩(colab)을 사용하는 경우는 별도 설치를 하지 않아도 바로 import해서 사용이 가능합니다. (구글코랩 관련 참고 포스팅)
사이킷런의 장점
1. 사용하기 쉽다 : 머신러닝은 수학과 통계에 기반하기 때문에 이를 하나하나 구현하려고 하면 엄청 복잡하고 어렵습니다. 사이킷런은 이런 복잡한 과정들을 모듈화해놔서 사용자들이 손쉽게 호출해서 사용하도록 구현했습니다. 또한 함수명과 사용방법이 직관적이고 간단해서 초보자들도 금방 습득할 수 있습니다.
2. 폭넓은 기능 : 다양한 종류의 머신러닝 알고리즘을 지원하고, 머신러닝에 필요한 데이터 프로세싱과 분석툴도 함께 제공합니다.
3. 오픈 소스, 넓게 형성된 커뮤니티 : 완전하게 무료로 오픈된 오픈 소스 라이브러리이기 때문에 부담없이 사용이 가능합니다. 또 머신러닝을 하면서 발생하는 이슈나 에러에 대해 의견을 나눌 수 있는 커뮤니티가 넓게 형성되어있고, 필요시마다 계속 업데이트를 하기 때문에 점점 더 발전해나간다는 장점이 있습니다. 실제로 사이킷런은 학생들 뿐만 아니라 실제 IT 빅테크 기업들에서도 적용하여 사용하고있는 라이브러리입니다.
사이킷런을 이용한 머신러닝 프로세스
그럼 이제 사이킷런을 설치한 이후 어떻게 머신러닝을 적용해볼 수 있는지 단계별로 코드 예시와 함께 보여드리겠습니다.
사이킷런에서 제공하는 데이터
사이킷런에서는 datasets라는 모듈을 통해 쉽게 로드할 수 있는 데이터셋들을 제공하고 있습니다. 이 데이터들은 리서치와 교육 목적으로 자주 사용되는 데이터입니다.
아이리스 데이터 : 아이리스 꽃은 3가지 종으로 이루어져있는데, 잎파리의 길이와 너비 등의 정보와 함께 각 속성들이 아이리스 종에 어떤 영향을 미치는지 볼 수 있는 데이터입니다.
보스턴 하우징 데이터 : 보스턴 부동산 가격 예측을 해볼 수 있는 데이터입니다. 지역마다 범죄율이나 도로 접근성, 공기 오염도 등을 가지고 있습니다.
와인 데이터 : 와인의 알콜 농도, 색깔 등의 속성들을 가지고 있고, 와인은 3가지의 클래스로 종류가 나눠져있습니다. Classification 또는 Clustering을 해보기 좋은 데이터입니다.
유방암 데이터 : 종양이 악성인지 아닌지를 classification 해보는 데이터입니다. 세포의 구체적인 정보들을 담고 있습니다.
손글씨 숫자 데이터 : 손으로 쓰여진 0부터 9까지의 숫자 이미지를 정보로 가지고 있습니다. 숫자들에 대해 classification해볼 수 있는 데이터입니다.
캘리포니아 하우징 데이터: 캘리포니아 부동산 가격을 예측해보기 위한 데이터입니다. 동네마다 인구 수, 소득 수준, 부동산의 연식 등을 정보로 가지고 있습니다.
데이터 로드
위에서 살펴본 데이터 중에서 이 포스팅에서는 아이리스 데이터를 이용하여 머신러닝을 적용해보도록 하겠습니다.
# 필요한 라이브러리 import
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
# Iris 데이터 로드
iris = load_iris()
# 판다스 데이터프레임에 Iris 데이터 넣어주기
iris_df = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns=iris['feature_names'] + ['target'])
# 처음 5개 행 출력해보기
print(iris_df.head())
데이터 로드에 필요한 numpy, pandas, load_iris를 우선 import합니다. `feature_names`를 통해 속성들의 이름을 가져올 수 있고, `target_names`로 타겟의 이름을 가져올 수 있습니다. 위의 코드는 scikit learn에서 제공하는 Iris 데이터를 가져와 데이터프레임에 넣어주는 코드이고 다음과 같은 결과를 print합니다.
데이터를 Train 세트와 Test 세트로 나누기(train_test_split)
그다음 해줘야할 일은 데이터를 Train 용과 Test 용으로 나누는 일입니다. 이렇게 나누는 이유는, 똑같은 데이터에 학습시키고 테스트를 시키면 테스트 결과는 항상 너무 좋게 나올 수 밖에 없기 때문에, 이 모델이 학습하지 않은 새로운 데이터에 대해서는 얼마나 예측율이 좋은지 테스트하기 위해 꼭 거쳐야하는 프로세스입니다.
가장 보편적으로 나누는 비중은 학습:테스트 = 7:3 비율입니다. 이렇게 특정 비율대로 데이터를 나누는 것을 사이킷런의 `train_test_split` 함수를 이용하면 코드 한줄로 쉽게 나눌 수 있습니다. 필요에 따라 이 비중을 수정하려면 test = 0.3 부분을 수정하면 됩니다.
# 데이터를 70% train, 30% test set으로 나누기
from sklearn.model_selection import train_test_split, cross_val_score
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
참고로 random_state = 42 부분은 기재해줌으로써 매번 코드를 실행할 때마다, 데이터를 똑같이 나눠주는 역할을 합니다. 해당부분을 명시해주지 않으면 매번 코드를 실행할 때마다 랜덤으로 비율에 맞게 train 세트와 test 세트로 다시 나누기 때문에 경우에 따라 매번 결과가 달라질 수 있습니다. 42 숫자는 아무런 의미는 없고, 특정 숫자를 기재해주기만 하면 해당 효과를 볼 수 있습니다.
모델(알고리즘) 선택 및 데이터 학습(fit)
그 다음은 모델(알고리즘)을 선택하고 데이터를 학습시키는 일입니다. 사이킷런에서는 다양한 종류의 알고리즘을 지원하지만 이 예제에서는 Decision Tree를 사용해보았습니다. 해당 Classifier를 먼저 import하고 DecisionTreeClassifier()로 선언해준 다음에 `fit` 메소드로 데이터를 학습시킬 수 있습니다. 여기서 attribute로는 위에서 학습데이터로 나누어진 X_train, y_train을 넣어줍니다.
# Train set를 Decision Tree Classifier에 학습시키기
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train)
Cross-Validation 하기
그 다음으로는 Cross-Validation을 해봅니다. Cross-Validation이 무엇인지, 왜 필요한 단계인지 궁금하시다면 이 포스팅을 참고하세요.
# Cross-Validation 수행해보기 (cv = 5은 5-fold cross-validation을 하겠다는 뜻, 늘리려면 5를 다른 숫자로 바꿔주기)
scores = cross_val_score(dt, iris.data, iris.target, cv=5)
# Cross-Validation 결과 출력해보기
print('Cross-validation scores: {}'.format(scores))
print('Average cross-validation score: {:.2f}'.format(np.mean(scores)))

코드를 실행해보면 Cross-Validation 회차마다의 Accuracy와 전체 평균 Accuracy를 볼 수 있습니다. 이 데이터는 굉장히 단순한 데이터이기 때문에 Accuracy가 엄청 높게 나오지만 복잡한 실생활의 데이터를 나오면 이정도 높은 Accuracy를 얻기는 정말 어려운 일입니다.
Test set에 테스트 해보기
Cross-Validation에서 어느정도 괜찮은 퍼포먼스가 나왔다면 그 다음에는 앞 단계에서 미리 나눠놨던 Test set에 테스트를 해보는 일입니다. 사이킷런의 `predict`함수에 미리 나눠놓은 X_test 데이터를 넣어주고 나온 결과 값(y_pred)을 실제 y값(y_test)과 비교해봄으로써 Accuracy를 측정해볼 수 있습니다.
# Test set에 Prediction 해보기
from sklearn.metrics import accuracy_score
y_pred = dt.predict(X_test)
# Test set 의 Accuracy 보기
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy: {:.2f}'.format(accuracy))위의 코드는 Accuracy:1.00 이라는 결과를 출력합니다.
Confusion Matrix와 Classification Report
사이킷런에서는 Classification 결과를 편리하게 분석할 수 있도록 Confusion Matrix와 Classification Report(Precision, Recall, F1-Score) 함수를 제공합니다. Confusion Matrix와 Precision, Recall, F1-Score의 개념과 왜 이 지표들을 봐야하는지 궁금하시다면 이 포스팅을 참고하세요.
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix, classification_report
# Confusion Matrix 계산하기
test_conf_matrix = confusion_matrix(y_test, y_pred)
# Confusion Matrix와 Classification report 출력하기
print('Test set confusion matrix:\n{}'.format(test_conf_matrix))
print('Classification report for test set:\n{}'.format(classification_report(y_test, y_pred, target_names=iris.target_names)))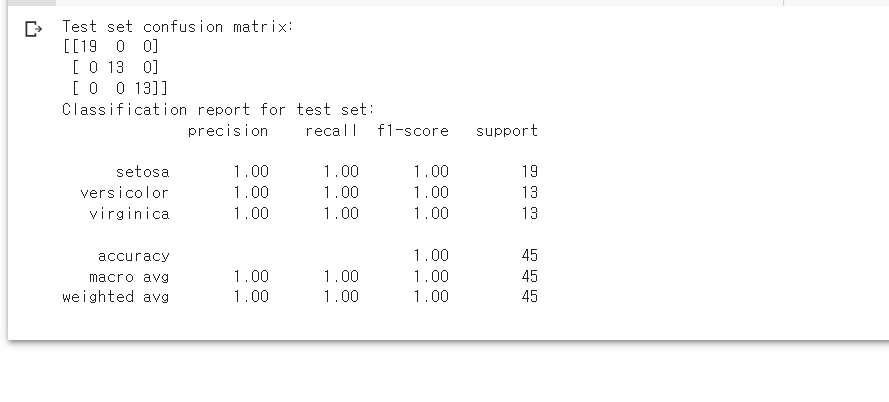
위와 같이 Confusion Matrix와 Classification Report를 편리하게 볼 수 있습니다. 이 결과 값들을 보면 이 모델이 각각의 class에 대해 얼마나 예측을 잘 하는지, 어떤 class에 대해서는 유독 예측율이 좋지 않은지 등 세밀하게 파악해볼 수 있습니다.
Summary
파이썬으로 머신러닝을 하려면 누구나 사용하는 사이킷런(Scikit-learn) 패키지에 대해 알아보았습니다. 사이킷런의 설치방법과 이용 가능한 데이터 종류, 머신러닝 각 단계별 사이킷런 함수를 어떤 것들을 쓰면 되는지 코드 예시와 함께 단계별로 정리해보았습니다. 오늘 정리한 내용은 머신러닝을 시작하는 초보자 분들에게 유용한 가장 기본적인 머신러닝 적용 핵심 절차라고 보시면 됩니다. 사이킷런에서 제공하는 머신러닝 모델 종류는 무궁무진하게 많고 기능도 정말 많기 때문에 향후 좀 더 난이도가 있는 내용도 다뤄보도록 하겠습니다.
[참고하면 좋을 포스팅]
머신러닝 Accuracy, Precision, Recall, F1-Score 이해하기 (Classification Model 평가, Confusion Matrix)
오늘은 머신러닝 모델, 특히 Classification model의 퍼포먼스를 평가하는 방법에 대해 알아보고자 합니다. True/False Positive, True /False Negative 그리고 Accuracy, Precision, Recall, F-1 Score의 개념에 대해 설명드
datasciencediary.tistory.com
노코드 머신러닝 툴 WEKA 사용방법(코딩 없이 Machine Learning하기)
코딩을 할 줄 몰라도 머신러닝을 할 수 있는 방법이 있습니다. 잘 만들어진 GUI 툴을 이용하는 것인데요. 데이터만 로드하면 수십가지 머신러닝 모델을 적용해보고 퍼포먼스를 평가해보고 결과
datasciencediary.tistory.com
'머신러닝' 카테고리의 다른 글
| [머신러닝] KNN 알고리즘 (K-Nearest Neighbor) (0) | 2023.02.20 |
|---|---|
| 머신러닝 서포트벡터머신 모델(Support Vector Machine) (0) | 2023.02.19 |
| 노코드 머신러닝 툴 WEKA 사용방법(코딩 없이 Machine Learning하기) (0) | 2023.02.15 |
| Logistic Regression 이해하기 : Sigmoid 함수, ROC 커브, Threshold 찾기 (0) | 2023.02.13 |
| 머신러닝 Accuracy, Precision, Recall, F1-Score, Confusion Matrix 이해하기 (0) | 2023.02.13 |




댓글