데이터 구조는 R 프로그래밍을 할 때, R-studio에서 데이터를 효율적으로 저장하고 조작할 수 있도록 데이터를 구성하는 방법입니다. R에는 Vector(벡터), Matrix(행렬), List(리스트) 및 Data Frame(데이터 프레임)의 데이터 구조가 있습니다.
R-studio 사용법, R 프로그래밍 데이터 구조 개념 이해하기
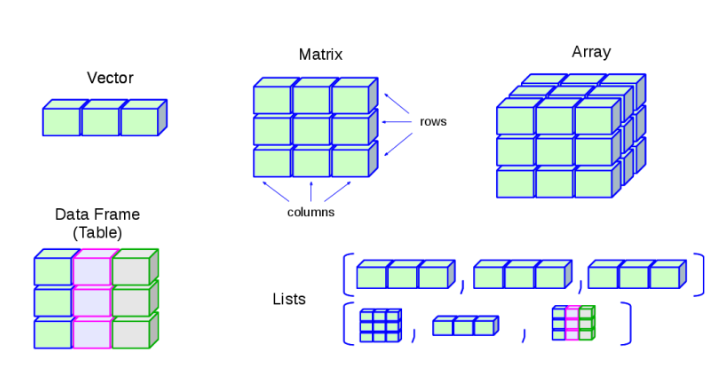
- Vector(벡터)는 R에서 가장 간단한 데이터 구조로, 숫자, 문자, 논리 등 모든 유형을 원자로 가질 수 있는 1차원 배열 형태의 데이터 구조입니다. 다만 하나의 벡터 안에는 같은 데이터 타입의 데이터로만 구성될 수 있습니다. (숫자는 숫자끼리, 문자는 문자끼리)
- Matrix(행렬)은 2차원 배열입니다. 흔히 많이 쓰는 표 형태의 행과 열 구조를 가진 데이터를 표현하는 데 자주 사용됩니다. 다만 같은 데이터타입의 데이터로만 구성될 수 있습니다.
- Array(배열)은 n차원의 데이터 구조입니다. 그리고 같은 데이터 타입의 데이터로만 구성될 수 있습니다.
- List (리스트)는 1차원의 데이터 구조도 가능하고, n차원의 데이터 구조도 가능합니다. 그리고 서로 다른 데이터 타입의 데이터들이 묶일 수 있는 데이터 구조입니다.
- Data Frame (데이터 프레임)은 서로 다른 데이터들을 함께 담을 수 있는 테이블 형태의 데이터 구조입니다. 행과 열의 개념을 가지기 때문에 데이터 분석시 가장 유용하게 사용되는 데이터 구조입니다.

R 프로그래밍 - Vector(벡터) 알아보기(코드 예제)
숫자형 벡터(Numeric Vector)
# 숫자형 벡터 생성
a <- c(1, 2, 3)
class(a) # [1] "numeric"
# 숫자형 벡터 인덱싱
a[2] # [1] 2
# 숫자형 벡터 연산
b <- a * 2
b # [1] 2 4 6
문자형 벡터(Character Vector)
# 문자열 벡터 생성
a <- c("apple", "banana", "cherry")
class(a) # [1] "character"
# 문자열 벡터 인덱싱
a[2] # [1] "banana"
# 문자열 벡터 연산
b <- paste(a, "is a fruit.")
b # [1] "apple is a fruit." "banana is a fruit." "cherry is a fruit."
논리형 벡터(Logical Vector)
# 논리형 벡터 생성
a <- c(TRUE, FALSE, TRUE)
class(a) # [1] "logical"
# 논리형 벡터 인덱싱
a[2] # [1] FALSE
# 논리형 벡터 연산
b <- !a
b # [1] FALSE TRUE FALSE
팩터(Factor)
# 팩터 생성
a <- factor(c("male", "female", "male", "male", "female"))
class(a) # [1] "factor"
levels(a) # [1] "female" "male"
# 팩터 인덱싱
a[2] # [1] female
levels(a[2]) # [1] "female" "male"
# 팩터 연산
b <- table(a)
b # a
female male
2 3
R 프로그래밍 - Matrix(행렬, 매트릭스) 알아보기(코드 예제)
# 매트릭스 생성
m <- matrix(1:9, nrow=3, ncol=3)
m
# [,1] [,2] [,3]
# [1,] 1 4 7
# [2,] 2 5 8
# [3,] 3 6 9
# 매트릭스 인덱싱
m[1,2] # [1] 4
m[2,] # [1] 2 5 8
m[,3] # [1] 7 8 9
# 매트릭스 조작
m[2,3] <- 10
m[,4] <- c(11, 12, 13)
m
# [,1] [,2] [,3] [,4]
# [1,] 1 4 7 11
# [2,] 2 5 10 12
# [3,] 3 6 9 13
R 프로그래밍 - Array (배열) 알아보기(코드 예제)
# 3차원 배열 생성
my_array <- array(1:27, dim = c(3,3,3))
print(my_array)
# 출력 결과
, , 1
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
, , 2
[,1] [,2] [,3]
[1,] 10 13 16
[2,] 11 14 17
[3,] 12 15 18
, , 3
[,1] [,2] [,3]
[1,] 19 22 25
[2,] 20 23 26
[3,] 21 24 27
# 3차원 배열 인덱싱
print(my_array[2,3,1])
# 출력 결과
[1] 8
# 3차원 배열 조작
new_array <- my_array * 2
print(new_array)
# 출력 결과
, , 1
[,1] [,2] [,3]
[1,] 2 8 14
[2,] 4 10 16
[3,] 6 12 18
, , 2
[,1] [,2] [,3]
[1,] 20 26 32
[2,] 22 28 34
[3,] 24 30 36
, , 3
[,1] [,2] [,3]
[1,] 38 44 50
[2,] 40 46 52
[3,] 42 48 54
R 프로그래밍 - List (리스트) 알아보기(코드 예제)
# 리스트 생성
a <- list(name = "John", age = 30, gender = "male", married = TRUE)
class(a) # [1] "list"
# 리스트 인덱싱
a$name # [1] "John"
a[[1]] # [1] "John"
a[[2]] # [1] 30
# 리스트 조작
a$age <- 31
a$height <- 175
a
R 프로그래밍 -Data Frame (데이터프레임) 알아보기(코드 예제)
# 데이터프레임 생성
df <- data.frame(name=c("John", "Mike", "Kate"),
age=c(25, 30, 35),
height=c(170.2, 175.5, 162.3))
df
# name age height
# 1 John 25 170.2
# 2 Mike 30 175.5
# 3 Kate 35 162.3
# 데이터프레임 인덱싱
df[1,] # 첫 번째 행
# name age height
# 1 John 25 170.2
df[,2] # 두 번째 열
# [1] 25 30 35
df$name # name 열
# [1] "John" "Mike" "Kate"
# 데이터프레임 조작
df$weight <- c(70.5, 80.2, 65.7) # weight 열 추가
df
# name age height weight
# 1 John 25 170.2 70.5
# 2 Mike 30 175.5 80.2
# 3 Kate 35 162.3 65.7
df$age[df$age > 28] # age 열에서 28보다 큰 값
# [1] 30 35
'R프로그래밍' 카테고리의 다른 글
| [R 프로그래밍 기초] R, R-studio 다운로드 설치방법 알아보기 (0) | 2023.04.06 |
|---|

댓글