이번 포스팅에서는 머신러닝 Classification 모델 중 Decision Tree(의사결정트리)와 관련된 데이터사이언티스트 단골 면접(인터뷰) 질문 및 꼭 알고 넘어가야 하는 핵심 개념들에 대해 정리해 보겠습니다.

엔트로피(Entropy)와 인포메이션 게인(Information Gain)은 무엇인지?
엔트로피(Entropy)는 데이터의 불순도 또는 무질서를 측정하는 단위입니다. 따라서 데이터가 섞여있을 수록 높은 엔트로피를 가지고, 데이터가 하나의 클래스로 이루어져 있을수록 낮은 엔트로피를 가집니다.
인포메이션 게인(Information Gain)은 Classification Tree에서 부모 노드에서 자식 노드로 내려왔을 때 불순도(엔트로피)를 얼마나 낮춰줬는지를 측정하는 지표입니다.
Decision Tree(의사결정트리)가 트리를 그리는 방법은?
Decision Tree(의사 결정 트리)는 높은 인포메이션 게인(Information Gain)을 가지는 노드(속성)부터 위에 위치시킵니다. 이 기준으로 계속해서 노드를 그려나가다가 아래 조건중 하나라도 해당하게 되면 가지치기(split)를 멈춥니다.
<Decision Tree가 가지치기(Split)을 멈추는 조건>
1. Maximum Depth : 만약 Decision Tree Maximum Depth를 설정해 둔 경우는, 해당 깊이에 도달하면 가지치기를 멈춥니다.
2. Minimum Number of Instances : 가지를 쳤을 때 미리 설정한 최소 인스턴스 갯수보다 작아지면 가지치기를 멈춥니다. 1번과 2번 설정은 Decision Tree가 오버피팅(Overfitting)하는 것을 방지하기 위해 해주는 설정입니다.
3. 가지를 쳤을 때 Information Gain 향상이 없을 때
4. 마지막 노드에 있는 인스턴스들이 모두 같은 class일 때
이 의사 결정 트리 알고리즘은 리프 노드의 모든 데이터 포인트가 동일한 클래스 레이블에 속하거나 미리 정의된 중지 기준을 충족할 때까지 이 프로세스를 각 하위 노드에 재귀적으로 적용합니다.
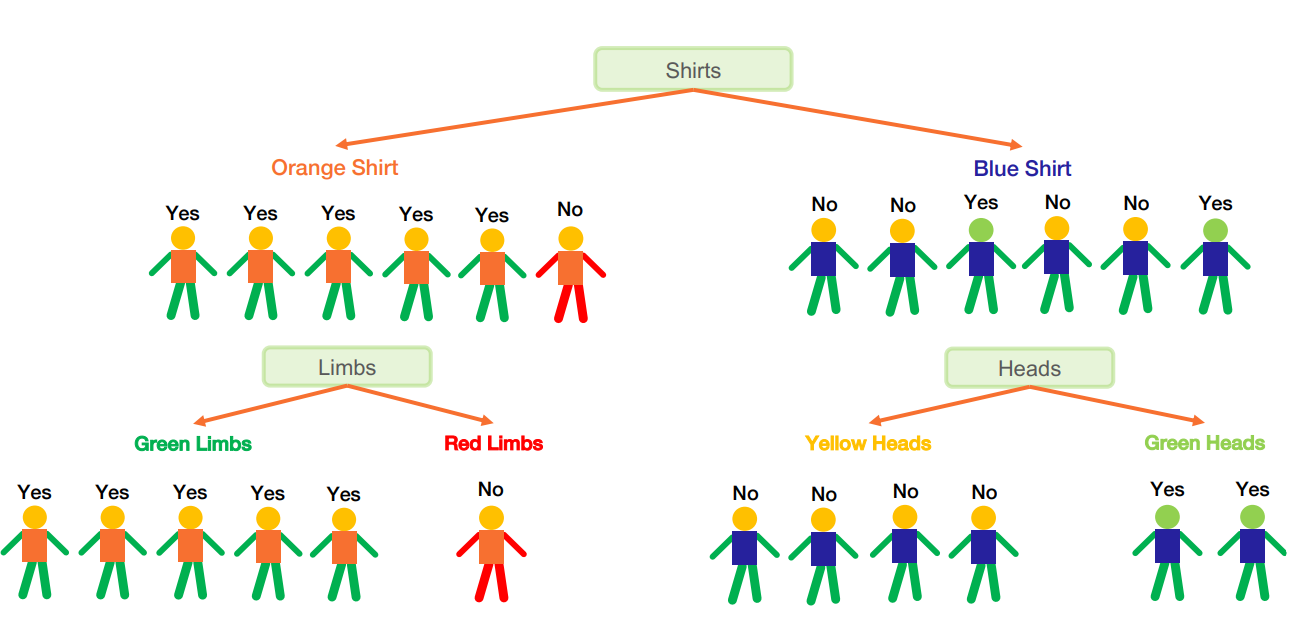
Classification Tree가 class와 probability를 예측하는 방식은?
데이터의 각 인스턴스는 트리의 루트노드(root node)부터 들어가 조건을 비교하면서 조건을 충족하는 쪽으로 내려가고 리프노드(leaf node)에 도달하면 해당 리프노드가 결정하는 클래스로 예측을 하게 됩니다.
Probability를 예측하는 방법은 인스턴스가 도착한 리프노드가 prediction을 수행한 전체 인스턴스 갯수개수 중에 positive인 것의 개수로 Probability를 측정합니다. 만약 해당 노드에 도착한 인스턴스들이 모두 positive 인스턴스였다면 probability = 1이 되고, 10개가 도착했는데 그중 2개만 positive였다면 probability = 0.2가 됩니다.
Training set과 Test set에 대한 모델 퍼포먼스는 어떤 차이가 있는지?
Training set 퍼포먼스가 항상 Test set 퍼포먼스 보다는 높을 수밖에 없습니다. 이는 머신러닝 모델이 Training data를 이미 학습했기 때문에 패턴을 잘 알고 있기 때문입니다.
Underfitting과 Overfitting 하지 않는 Decision Tree(결정 트리)를 만드는 방법은?
Decision Tree(결정 트리)의 노드수를 증가시키면서 Train set과 Test set에 대한 모델의 에러율을 측정하고 Plot을 그려봤을 때 Train set, Test set에 대한 에러율이 모두 감소하는 최대 지점이 가장 이상적인 노드수입니다.

해당 노드수 보다 적은 노드수의 트리를 그리면 언더피팅(Underfitting)할 수 있습니다. 트리가 충분한 노드를 가지지 못하게 되면 데이터의 대표적인 패턴을 다 잡아내지 못하여 train set과 test set 모두에 좋지 않은 퍼포먼스를 보입니다.
해당 노드수보다 커지게 되면 Train set에 대한 에러율은 감소하는데 Test set에 대한 에러율은 오히려 증가하는 오버피팅(Overfitting)을 보이게 됩니다. 이는 오버피팅하게 되면 train set 데이터에 있는 대표적이지 않은 데이터 패턴까지 (노이즈, 아웃라이어) 모두 학습하게 돼서 모델이 학습하지 않은 새로운 데이터에는 제대로 generalize 하지 못하게 되기 때문에 생기는 현상입니다.
Train-Test split 방법과 Cross-Validation 방법은 각각 무엇이고 목적이 무엇인지?
머신러닝 모델을 평가하는 주 목적은 이 모델이 학습하지 않은 새로운 데이터에 대해서 얼마나 예측을 잘 수행할지 가늠해 보는 것입니다. Train-Test split은 학습용 데이터와 테스트용 데이터를 따로 나누고 모델 학습을 시킬 때는 Train set으로만 학습시키고 테스트는 미리 나눠놓은, 모델이 학습할 때 보지 않은 Test set에 테스트하는 것을 말합니다.
Cross-Validation은 데이터를 n개의 조각으로 나누고 n번의 반복을 하면서 한조각씩 떼내어 n-1조각의 데이터에 대해 학습시키고 1개의 조각의 테스트 데이터에 테스트하는 것을 의미합니다. n번 반복할 때마다 1개의 조각은 계속 다른 조각으로 바뀌고 최종적으로 반복하면서 얻은 퍼포먼스의 평균치를 Cross-Validation 퍼포먼스로 평가하는 방법입니다.

Cross-Validation은 보통 모델을 배포(deploy)하기 전에 머신러닝 모델이 일정 수준 이상의 퍼포먼스를 가지는지 테스트하고 또 여러가지 모델 후보를 두고 배포했을 때 어떤 모델이 가장 퍼포먼스가 좋을지 비교해 보기 위해 사용합니다.
이과정을 통해 후보 모델이 선정되고 일정 수준에 도달하여 배포하기로 결정이 되었을 때, 최종적으로 학습과정에서는 전혀 사용되지 않은 별도의 Test set에 테스트를 해볼 때 Train-Test Split 방법이 사용됩니다.

'머신러닝' 카테고리의 다른 글
| 머신러닝 Ensemble method, Bagging (배깅), 성능 향상 방법 (0) | 2023.02.26 |
|---|---|
| 머신러닝 Decision Tree 핵심 개념(Entropy, Information Gain) (1) | 2023.02.24 |
| 불균형 데이터(Imbalanced Data) 머신러닝 Classification 문제점 해결방법 (0) | 2023.02.23 |
| 머신러닝 Feature Selection 개념, 중요성, 하는 방법 (0) | 2023.02.22 |
| 머신러닝 ROC curve(커브), AUC 개념 제대로 이해하기 (0) | 2023.02.22 |




댓글